Introduction
In this post, I will continue my previous exploration of 3D content generation methods available in threestudio, a powerful and versatile framework for 3D content creation. This time I’m exploring 3D object generation from a single image. For consistency, I will use an image of this armchair, that looks similar to some results of text-to-3D generations from the previous post:

Methods and results
I tested the following methods, which are all available in the Three Studio framework:
Stable-zero123 – Method based on new Stability AI network: Stable-zero-123. Generation took only 7 minutes. It definitely created the best results. I will experiment more with it and try creating the final mesh from the results.
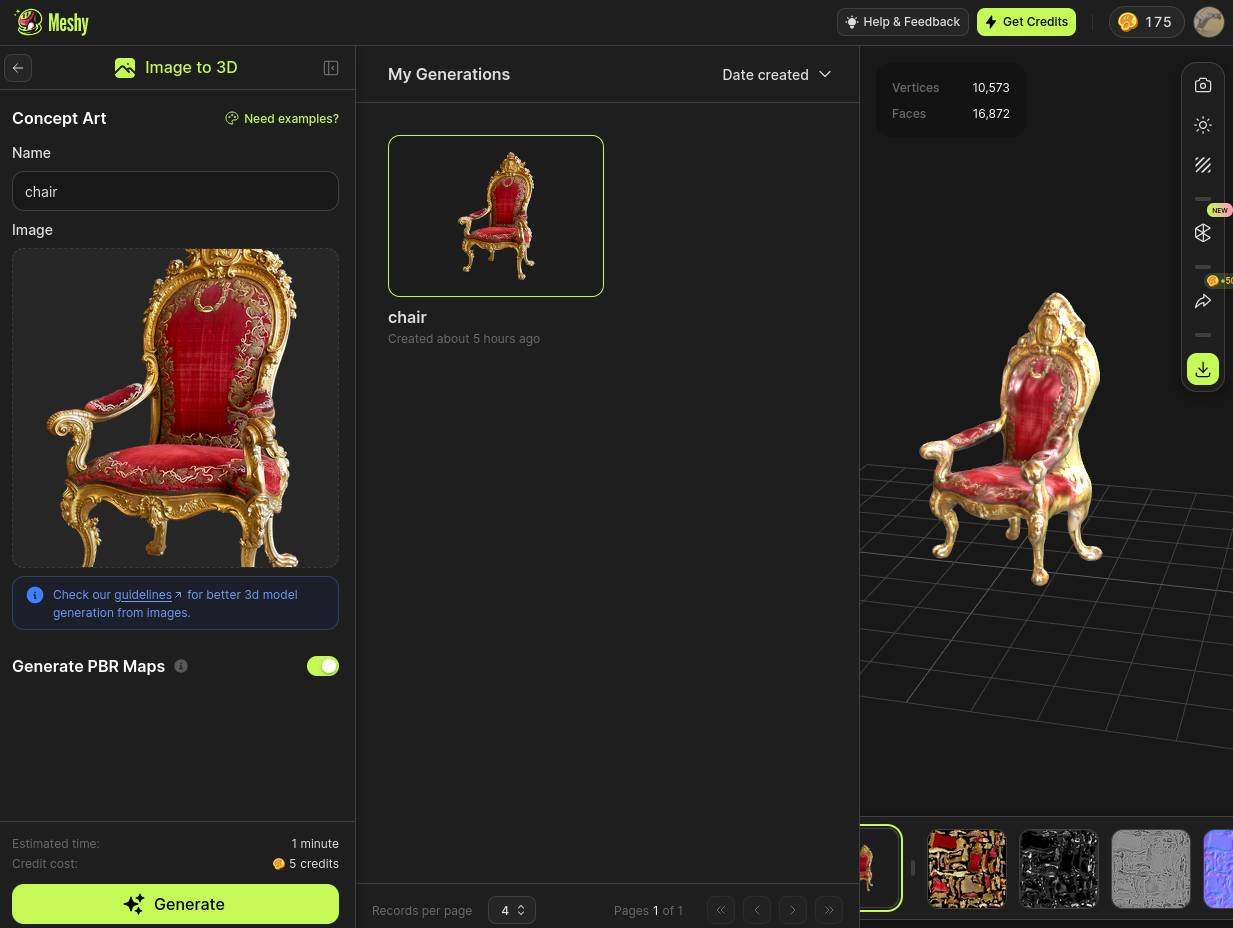
The results are very similar to output of meshy.ai:
Zero123XL did not perform that well. It failed to generate a basic shape of the armchair. It failed similarly to every other image-to-3d model tested after it: it flattened the chair in one axis.
Magic123-HiFA – Generation took about 1.5 h and although the effect is not great, it is way better then most of text-to-3D methods from the last post.
Magic123 – Zero123 + Stable Diffusion. The results are very similar, as this method uses the same base model.
Summary
Based on this simple experiment, Magic3D is, again, a clear winner here. One important difference from text-to-3d models is the lack of the Janus effect. None of the models had that issue
It is interesting, that the results generated by the commercial solution – meshy.ai – look very similar to the results of Magic3D method.
One, possible reason why this method detected shape so well, while all others failed might be, that textual Inversion is not supported for it, so I had to provide a text prompt with a description of the object. Possibly this is why it was able to generate such a nice shape for the chair – it just knew, that it was generating a chair 🙂 I’ll try to verify this.