Preparation
Creating a complete scene from scratch should be a nice way to check the limitations of this technology.
I’m starting with the generation of concept art for some assets with SDXL, with prompts such as:
- A color concept art drawing of a stylized wooden chair of a witch, old, wooden, solo, white background, artstation
- A color concept art drawing of a stylized big wooden table of a witch, old, wooden, solo, white background, artstation
- A concept art drawing of a stylized bottle of a magical potion, solo, single bottle, white background
I selected a few examples that looked good and presented some potential problems, that I wanted to test, like:

Asset with transparency

Multiple objects on a single image

Asset with complex shapes

Very unrealistic object

Complex spatial structure in single image

Image, that that does not make sense in 3D
I started by removing the background from each of the 27 images selected for this experiment. I did it by hand, in Photopea. It was easy for most of them, but some had complex backgrounds and required a bit of work.

I created a script, that executed generation for every file:
#!/bin/bash
dir="./images/"
for fullpath in "$dir"*
do
filename=$(basename "$fullpath")
python launch.py --config configs/stable-zero123_small.yaml --train --gpu 0 data.image_path="$dir$filename" use_timestamp=False name=asset_generation tag="$filename"
doneConfig file stable-zero123_small.yaml is a modified version of stable-zero123.yaml with two times smaller batch size, to make it for in my VRAM, accumulate_grad_batches set to 4, max_steps increased to 4800 and every_n_train_steps to 600, to lower the number of generated previews.
Results
Simple, single assets generated nice results. Front view of the asset is usually more detailed then back view.

Some are a bit flatter than I’d expect, but still look good. I suppose, that „baked” shadow might be a result of the thick, black outline on that image. I’ll have to redo this test with more realistic examples to verify this.

Transparency was handled well, but I expect, that generation of mesh will be problematic.

If there are some additional elements, floating around the asset, they usually land on the plane parallel to the view. However, they did not reduce the quality of the result.

Rendering multiple simple assets from one image created results with similar quality. The network did not manage to handle the edges of the bottles: It did not figure out how the border should be treated.
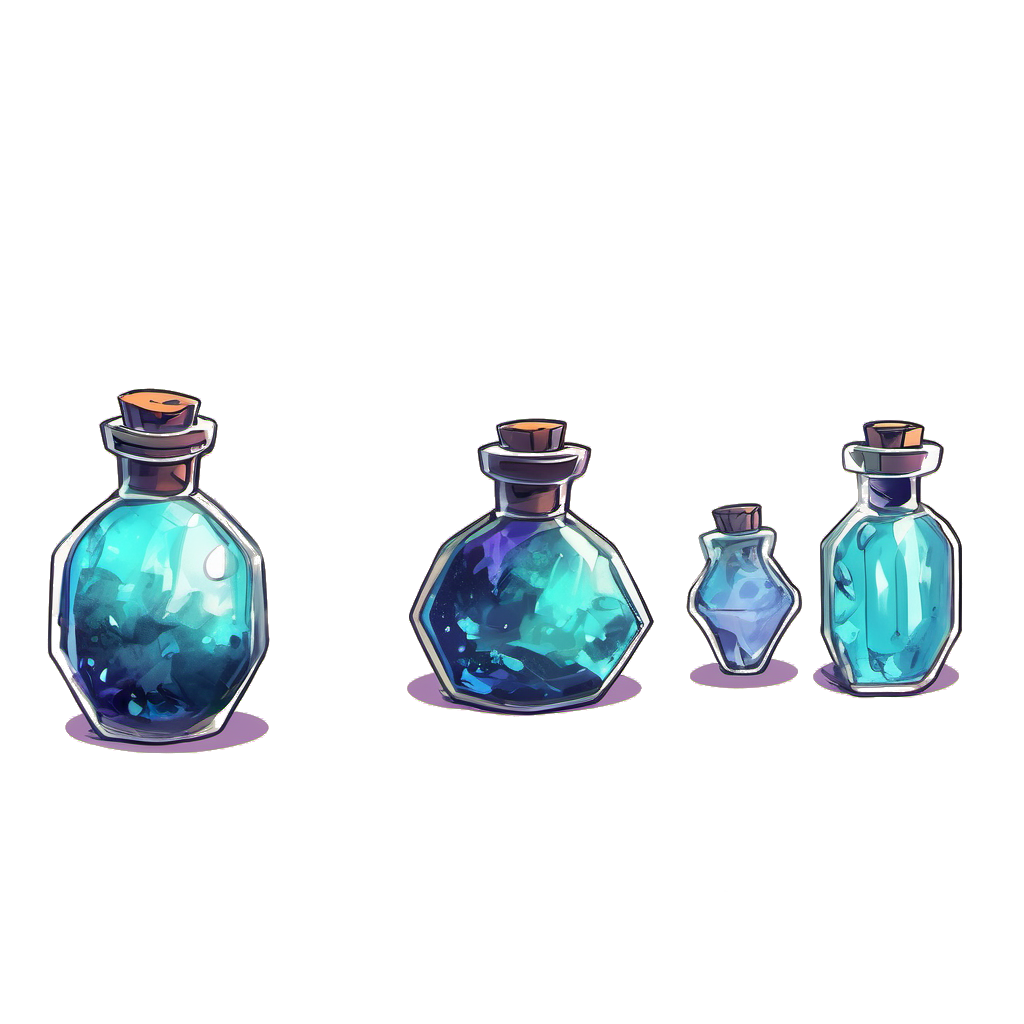
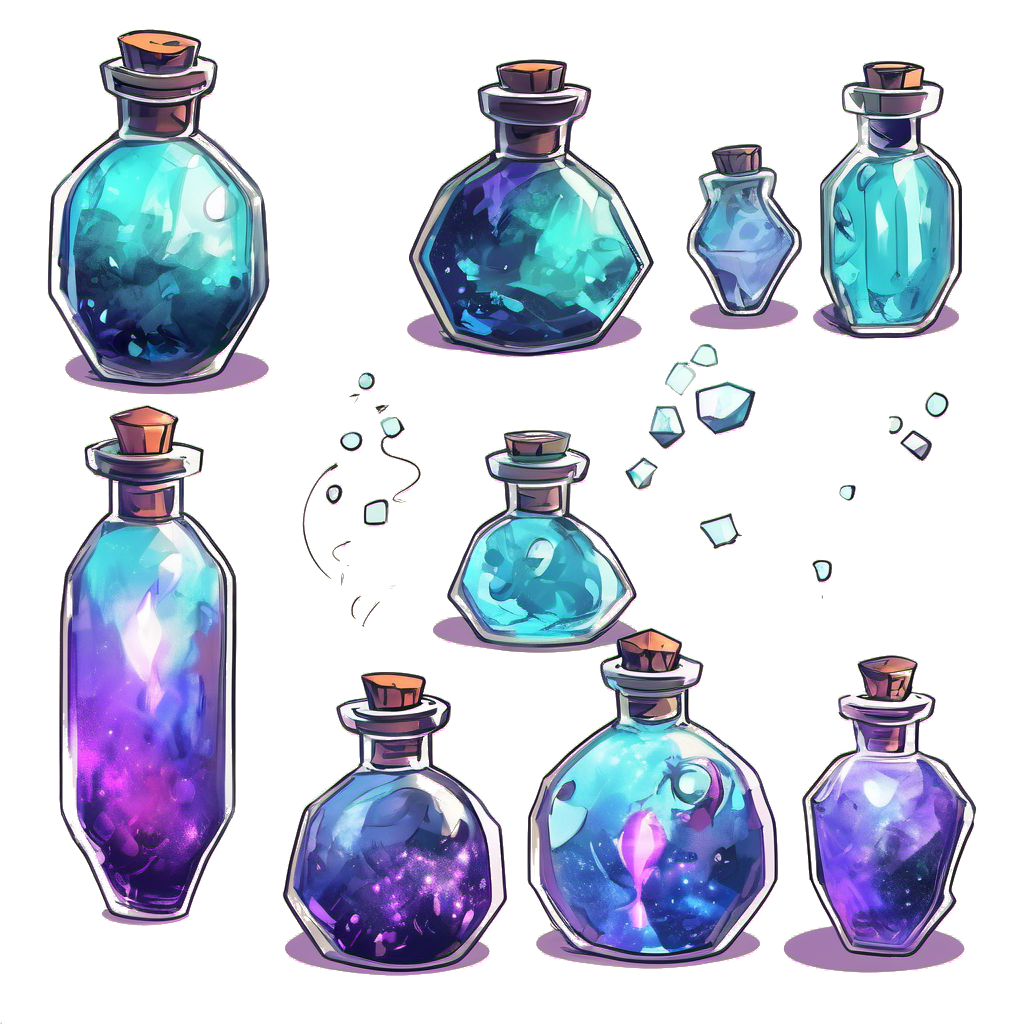
I also tried more complex assets in large numbers. The results are way worse. With this said, the network was not able to generate nice assets from this table even when it was separated. It might be too stylized.

Some other assets in a similar style generated nicer results. The stylized shadow was not recognized correctly: I should have removed them before generation.



As expected: The heavily stylized assets that did not make sense in 3D did not generate nice results.

Some of such images generated even weirder results:

Unfortunately, the process failed for most of the images (14 of 27 tested). They crashed with OOM errors. After lowering the batch size, the crashes stopped, but they did not generate any reasonable results:
The log was filled with warnings:
"[WARNING] Empty rays_indices!" This included all the cats 🙁
I’ll try to debug the cause of that soon.