In this post, I’m going to iterate on the promising results from my previous post.
Let’s start with understanding the method better.
How does it work?
In short, the method is based on optimizing a neural field (NeRF) with randomly sampled viewpoints generated by Stable Zero123 network. This NeRF can be later converted to a textured mesh.
Zero-1-to-3
https://zero123.cs.columbia.edu/
https://huggingface.co/spaces/cvlab/zero123-live
The Zero-1-to-3 paper was released on March 20, 2023.
This method generates new views with changed viewpoints/camera angles based on a single RGBA image. It is based on the Conditional Diffusion Model, fine-tuned on the synthetic dataset to learn controls of the relative camera viewpoints. This is possible due to the geometric priors that large-scale diffusion models learn about natural images. Despite being trained on synthetic data, Zero-1-to-3 retains strong zero-shot generalization ability to out-of-distribution datasets and in-the-wild images.
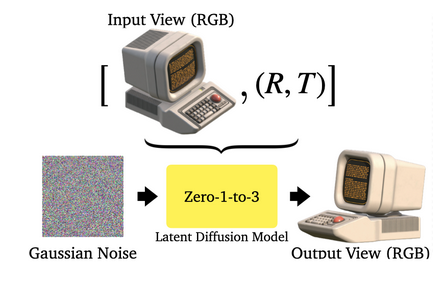
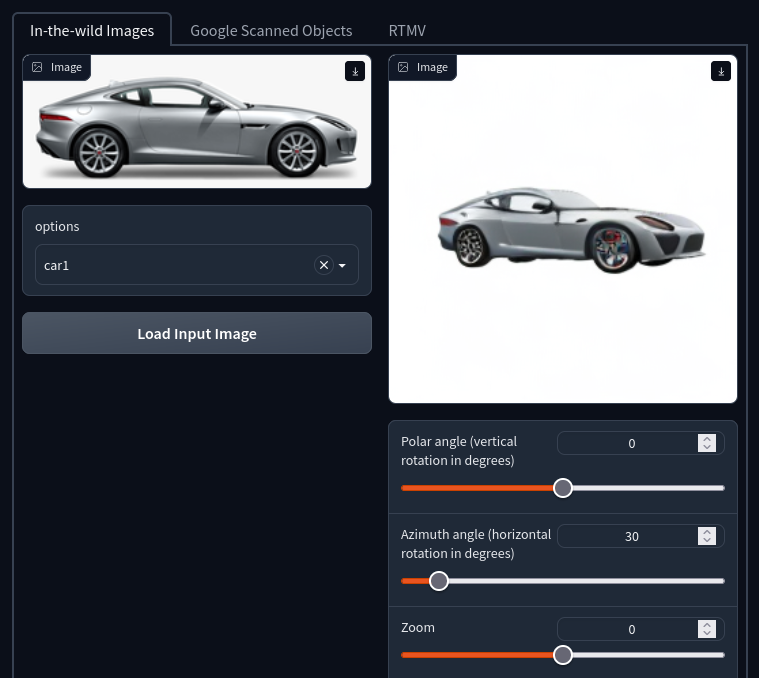
Stable Zero123
https://stability.ai/news/stable-zero123-3d-generation
On December 13, 2023, Stability AI introduced the Stable Zero123 model, an advancement in the realm of object view synthesis. This innovative model distinguishes itself by delivering remarkably enhanced image quality compared to its forerunners, the Zero1-to-3 and Zero123-XL. The leap in performance is a direct result of improved training datasets (based on Objaverse) and elevation conditioning techniques. The model can be used for non-commercial and research use, but a commercial version is also available.

Score Distillation Sampling (SDS) – Generating 3D objects from views
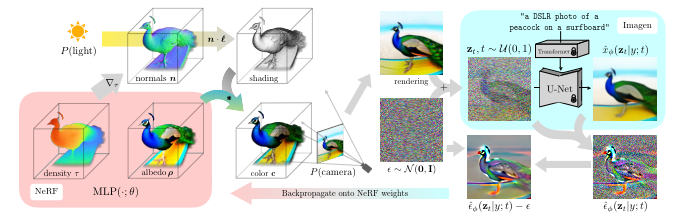
The implementation of 3D object generation available in threestudio was created by creators of the network. It uses Score Distillation Sampling (SDS) to optimize a neural field (NeRF). Generating a mesh and texture from this NeRF can also be done, as a separate step. Stability AI team proposes using an SDXL network for the generation of a single image from text and then using the result as input for this method, as a way to accomplish Text-to-3D pipeline.
Score Distillation Sampling (SDS) is a way to generate samples from a diffusion model by optimizing a loss function.With SDS it is possible, to optimize samples in an arbitrary parameter space, such as a 3D space, as long as we can map back to images differentiable.
Using this loss in a DeepDream-like procedure,
we optimize a randomly-initialized 3D model (a Neural Radiance Field, or NeRF)
via gradient descent such that its 2D renderings from random angles achieve a low
loss.
In the original DreamFusion paper, released in September 2022, the randomly initialized 3D model, represented with NeRF, is optimized via gradient descent such that its 2D renderings from random angles achieve a low loss. The approach used a pre-trained and unmodified Imagen Diffusion 2D 64×64 pixels image generation model, so it did not require any training on 3D object datasets. Citing the authors:
Our approach requires no 3D training data and no modifications to the image diffusion model,
DREAMFUSION: TEXT-TO-3D USING 2D DIFFUSION arXiv:2209.14988v1
demonstrating the effectiveness of pretrained image diffusion models as priors.
If I understood everything correctly, those are the steps of the generation process:
– The process starts with a randomly initialized NeRF field with albedo color and density data.
– An image is generated from NeRF and combined with some random noise. The NeRF rendering happens by casting a ray for each pixel from the camera’s center of projection through the e pixel’s location in the image plane and out into the field. For multiple points sampled along the ray, values for albedo and density (opacity) are sampled.
– This noise image is used as an input for the diffusion model conditioned on the text prompt.
– This model is used to generate a prediction of injected noise (diffusion models usually try to predict noise, so the image can be de-noised).
– This result is de-noised again, by subtracting a noise added earlier to the result of NeRF generation.
– This image can be interpreted as changes, that the diffusion model made to the rendering to make it match the prompt better. It is back-propagated through the NeRF and used to modify weights of the NeRF.
Improving the 3D chair
In the previous post, I generated this 3D representation of the chair:
It already looks nice, but I’ll try to improve it as much as I can, with 24 GB of VRAM, and export it as a mesh with textures. This one was generated with default parameters, described in the project documentation with one change: I had to lower the batch size, due to OOM issues.
Firstly, I’ll try to compensate for the smaller batch size by increasing the value for accumulate_grad_batches parameter, as suggested by the documentation. I’ll also double the number of max_steps, setting it to 1200.
Generation took over two times longer – 16 minutes instead of 7 minutes -but the result is way less noisy.
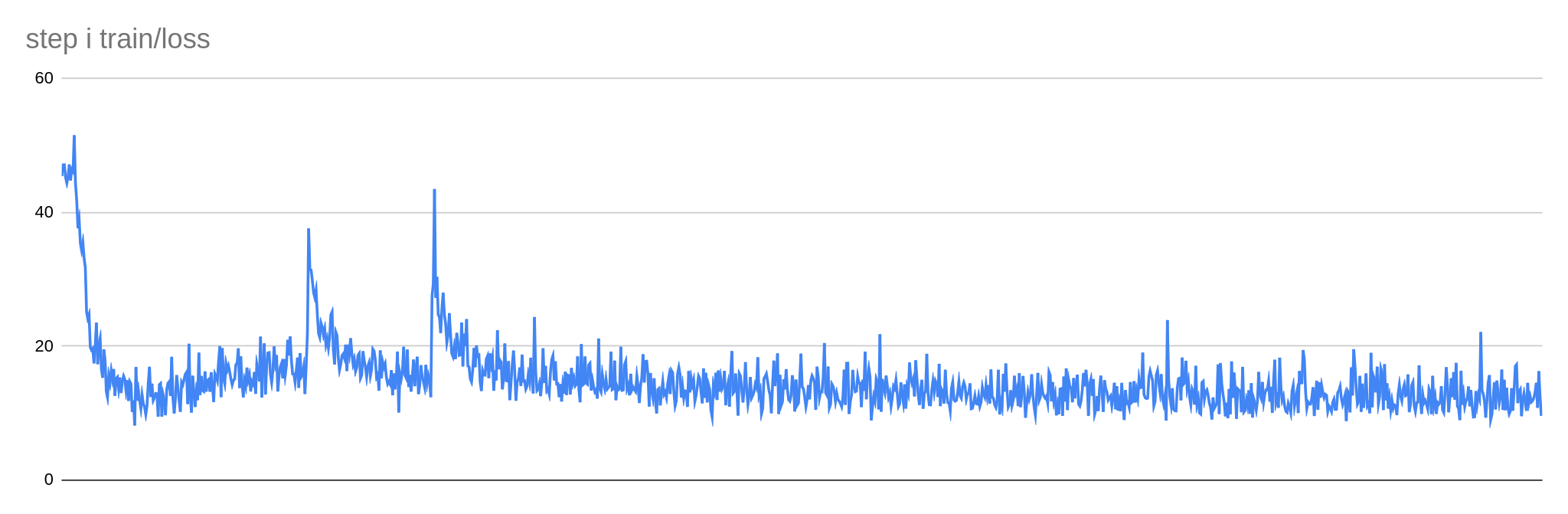
The result was still improving, so I’ll increase it. I’d also like to try other ways to improve the quality.
Config specifies resolutions used for training, batch sizes used with those resolutions, and steps when resolution changes in values:
data:
random_camera:
height: [64, 128, 256]
width: [64, 128, 256]
batch_size: [6, 4, 2]
resolution_milestones: [200, 300]With my VRAM I should be able to decrease the batch size for the last steps and increase the resolution of images two times, to 512 px.
data:
random_camera:
height: [64, 128, 256, 512]
width: [64, 128, 256, 512]
batch_size: [6, 4, 2, 1]
resolution_milestones: [200, 300, 600]But I was getting OOM errors every time I tried. I’ll be looking for a solution for that, maybe I can save some MBs somehow

.
I’ll end with this. In the next post, I’ll generate mesh and textures for this NeRF.